System Requirements: Mac, Linux, Windows with a minimum RAM of 8GB
Technology: We will use React JS for creating the frontend and run Ollama in the terminal, utilizing Ollama APIs.
I believe you are already familiar with React.js and npm packages. Our main focus will be on Ollama and how to access its APIs, so feel free to choose a different frontend framework to create a chat UI.
What is LLM – Large Language Model
- LLM typically stands for “Large Language Model.” These are advanced natural language processing models that are trained on extensive datasets to understand and generate human-like language. Examples of large language models include GPT-3 (Generative Pre-trained Transformer 3) developed by OpenAI, BERT (Bidirectional Encoder Representations from Transformers) by Google, and others. These models have billions of parameters and are capable of performing a wide range of language-related tasks, such as text generation, translation, summarization, and question-answering.
- LLMs, or Large Language Models, are sophisticated language models trained on vast datasets ranging from thousands of terabytes to petabytes of data. These models utilize parameters, and for our purposes, we will be employing Gemma, an open model developed by Google.
- Gemma is equipped with two sets of parameters: one with 2 billion parameters and another with 7 billion parameters. These parameters play a crucial role in shaping the model’s understanding and generation of language, enabling it to handle a wide array of linguistic tasks and contexts.
What is ollama?
- Ollama is a platform that enables users to run open-source large language models, such as Llama 2 and Gemma, locally on their machines. This offers a great deal of flexibility and control, allowing users to leverage the power of advanced AI models without relying on external cloud services.
- By visiting the Ollama library at https://ollama.com/library, users can explore and choose from multiple models available, each optimized for different types of tasks.
- These models vary in their specialties; for example, some are fine-tuned to excel in coding-related tasks, providing assistance with programming, debugging, or understanding codebases.
- This local deployment can significantly enhance privacy, reduce latency, and offer customization opportunities that might not be as readily available when using cloud-hosted models.
Step 1: Visit https://ollama.com/ to download Ollama to your local machine and install it.
Step 2: Open the terminal and verify if Ollama is installed by typing ‘ollama’.
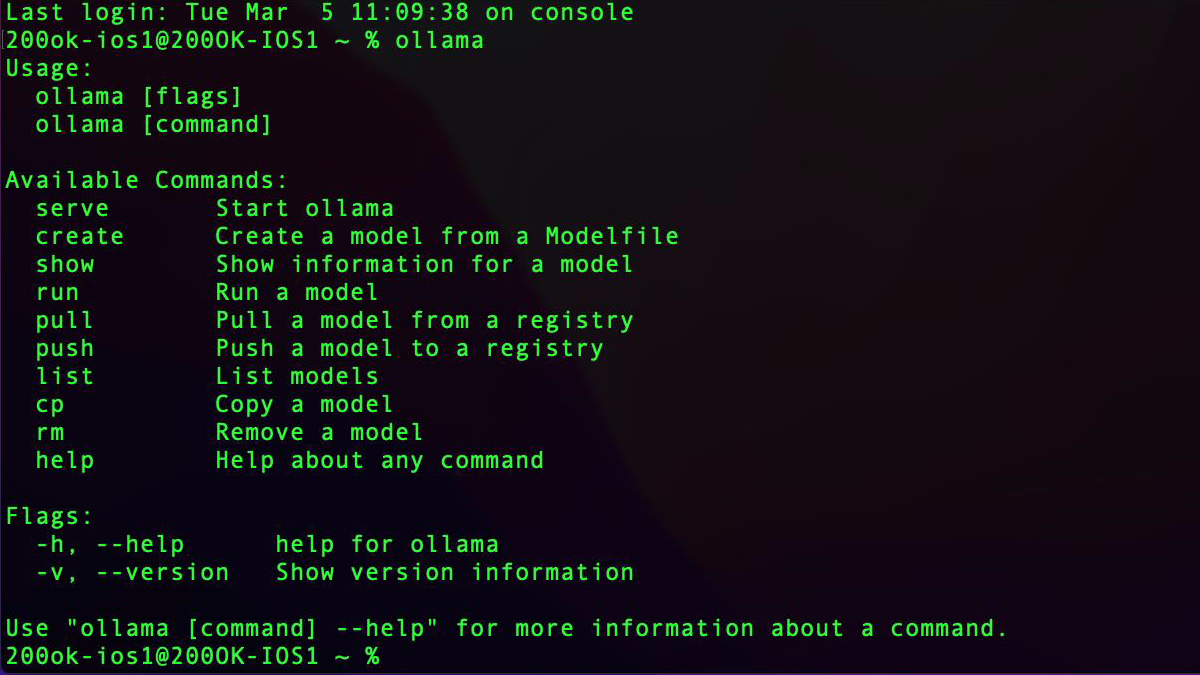
Step 3: Download Gemma locally by executing ‘ollama run gemma:2b’.
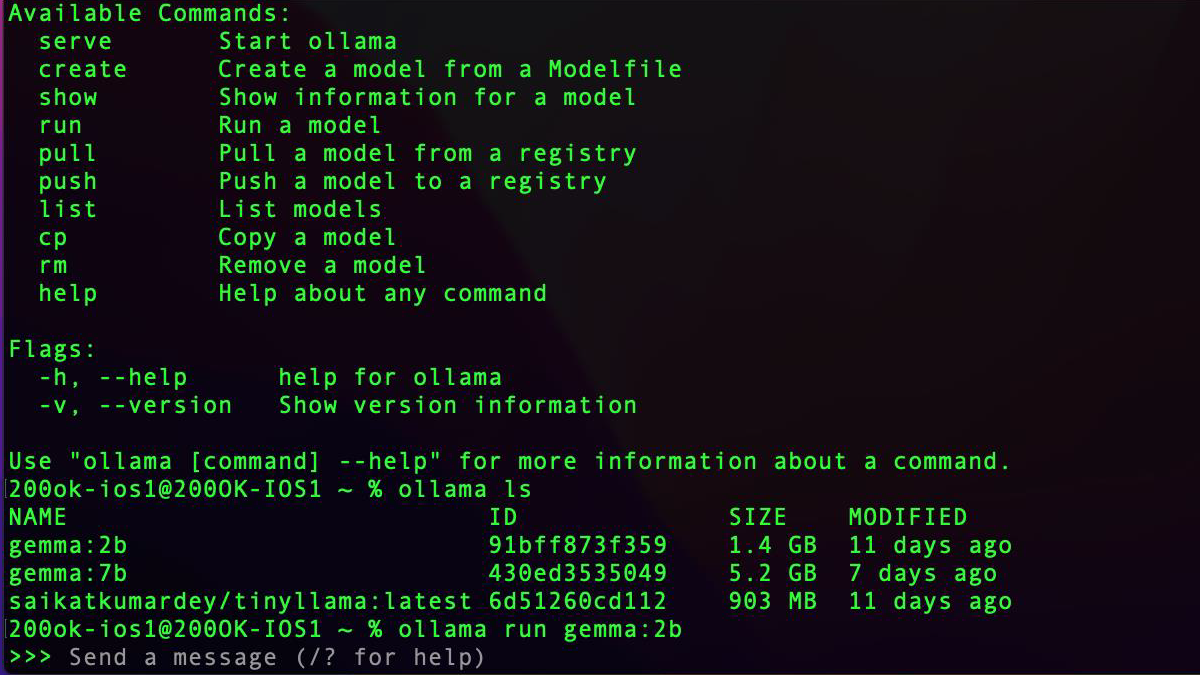
- This command will download a model approximately 1.4GB in size and then run this model in the terminal, allowing you to interact with the model by asking questions.
- However, if you aim to create a tool that can be used by multiple users, you will need to develop a UI and integrate APIs to interact with the model.
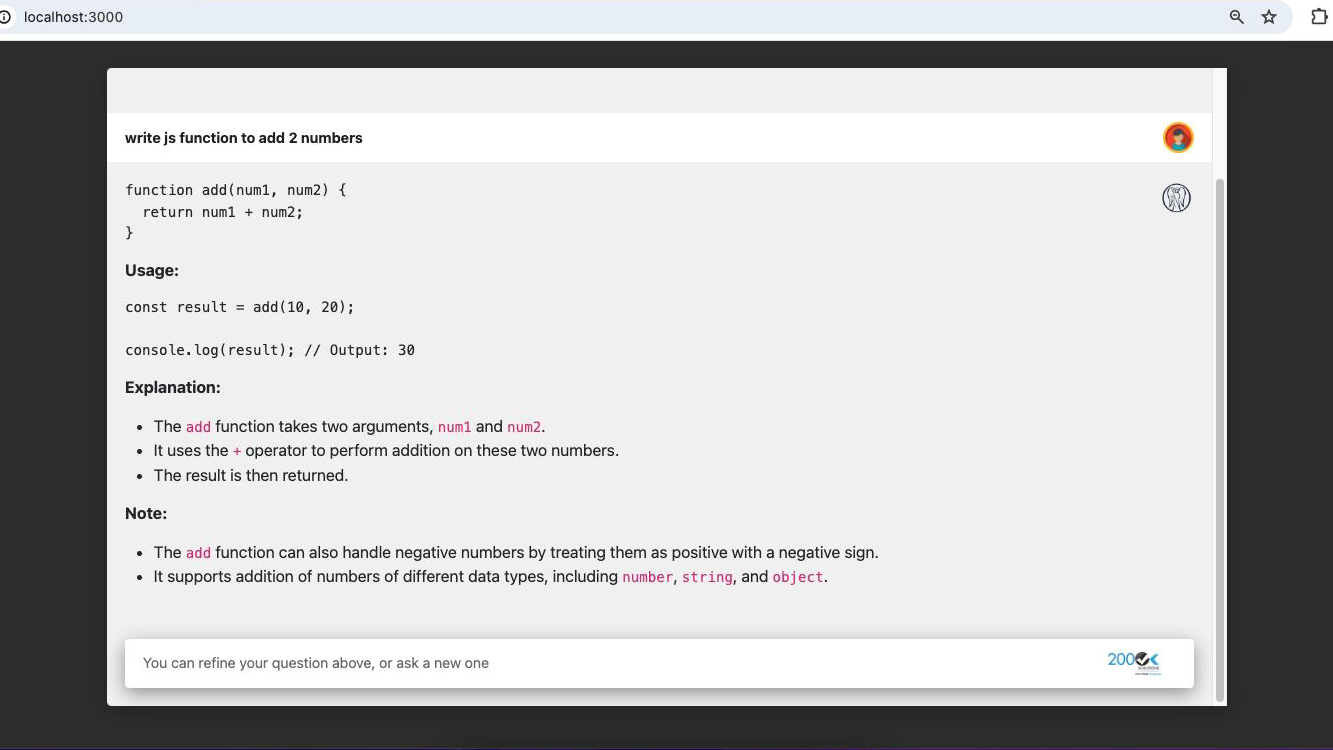
Step 4: create frontend ui with some basic design like search bar and question answer screen.
Step 5: We need to integrate the Ollama API with the frontend. By default, Ollama operates on http://localhost:11434/ You can refer to this documentation for the API:
https://github.com/ollama/ollama/blob/main/docs/api.md
- We will be using the POST /api/generate endpoint to create the chat.
const getChat = async (question) => {
if (!question) return;
const payload = {
model: "gemma:2b",
prompt: question,
stream: false,
};
try {
const response = await axios.post(
"http://localhost:11434/api/generate",
payload
);
return response?.data;
} catch {
console.log("error");
return "";
}
};Right now, we are using stream: false which means it will give single response instead of objects of response. You can enable stream and use streaming api to look and feel like chat gpt response writing.
So, output will look like this.